什么是Pandas?
一个开源的Python类库:用于数据分析、数据处理、数据可视化
- 高性能
- 容易使用的数据结构
- 容易使用的数据分析工具
很方便和其它类库一起使用:
- numpy:用于数学计算
- scikit-learn:用于机器学习
怎样下载安装Pandas
1、下载使用Python类库集成安装包:anaconda
https://www.anaconda.com
当今最流行的Python数据分析发行版
已经安装了数据分析需要的几乎所有的类库
2、pip install pandas
Pandas 读取数据
本代码演示:
- pandas读取纯文本文件
- 读取csv文件
- 读取txt文件
- pandas读取xlsx格式excel文件
- pandas读取mysql数据表
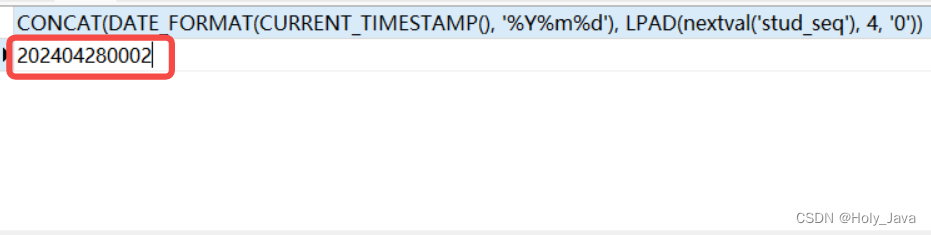
1 读取CSV,使用默认的标题行、逗号分隔符
import pandas as pd
fpath = "./datas/ml-latest-small/ratings.csv"
# 使用pd.read_csv读取数据
ratings = pd.read_csv(fpath)
# 查看前几行数据 模式是前五行,如果想显示前10行 head(10)
ratings.head()
# 查看数据的形状,返回(行数、列数)
ratings.shape
# 显示类型 DataFrame 是二维表类型 它是 pandas里特有的一种数据类型
type(ratings)
# 查看列名列表 , 第一行的表头
ratings.columns
# 查看索引列
ratings.index
# 查看每列的数据类型
ratings.dtypes
# 数据的具体情况
ratings.info()
# 查看个数,平均数,标准差,最小值,下次分位数,中位数,上次分位数,最大值
ratings.describe()
1.2 读取txt文件,自己指定分隔符、列名
import pandas as pd
fpath = "./datas/crazyant/access_pvuv.txt"
pvuv = pd.read_csv(
fpath,
sep="\t",
header=None,
names=['pdate', 'pv', 'uv']
)
print(pvuv)
2、读取excel文件
import pandas as pd
fpath = "./datas/crazyant/access_pvuv.xlsx"
pvuv = pd.read_excel(fpath)
print(pvuv)
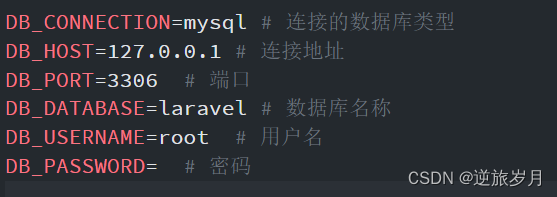
3、读取MySQL数据库
import pandas as pd
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
user='root',
password='000000',
database='test_db',
charset='utf8'
)
mysql_page = pd.read_sql("select * from emp", con=conn)
print(mysql_page)
03. Pandas数据结构
- Series
- DataFrame
- 从DataFrame中查询出Series
1. Series
- Series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数据标签(即索引)组成。
1.1 仅有数据列表即可产生最简单的Series
import pandas as pd
import numpy as np
s1 = pd.Series([1,'a',5.2,7])
print(s1) # 左侧为索引,右侧是数据
print(s1.values) # 获取数据
1.2 创建一个具有标签索引的Series
import pandas as pd
data = [f'NPC{i}' for i in range(5)]
index = list(range(1,5+1))
s = pd.Series(data=data,index=index)
print(s)
print(type(s))
1.3 使用Python字典创建Series
import pandas as pd
sdata = {'Ohio':35000,'Texas':72000,'Oregon':16000,'Utah':5000}
s3=pd.Series(sdata)
print(s3)
1.4 根据标签索引查询数据
- 类似Python的字典dict
import pandas as pd
s2 = pd.Series([1, 'a', 5.2, 7], index=['d','b','a','c'])
s2['a'] # 5.2
type(s2['a']) # float
print(s2[['b','a']])
type(s2[['b','a']]) # pandas.core.series.Series
- 标签索引
import pandas as pd
data = [f'data{i}' for i in range(4)]
index = [f'idx{idx}' for idx in range(4)]
s = pd.Series(index = index, data = data)
print(s)
print(s['idx0'])
# 获取多个标签索引
print(s[['idx0','idx1']]) # 在索引位置添加一个列表,列表中放入多个索引
# 索引切片
print(s[0:3:1]) # [start:stop:step] 包头不包尾
# 标签索引切片
print(s['idx0':'idx3']) # 神奇的地方来了,可以使用文字来表示索引,同时范围含头含尾
# 获取index元素
indexs = s.index
print(indexs)
print('可以通过list()函数将index转为列表')
print(list(indexs))
# 获取value元素
values = s.values
print(values)
print(type(values))
print('因为value的类型是numpy.ndarray观察values的形式是通过空格来分隔的就可以得知')
print('可以通过list()将其转为列表对象')
print(list(values))
2. DataFrame
DataFrame是一个表格型的数据结构
- 每列可以是不同的值类型(数值、字符串、布尔值等)
- 既有行索引index,也有列索引columns
- 可以被看做由Series组成的字典
创建dataframe最常用的方法,见02节读取纯文本文件、excel、mysql数据库
2.1 根据多个字典序列创建dataframe
import pandas as pd
data={
'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]
}
df = pd.DataFrame(data)
print(df)
# 查看表头
print(df.columns)
print(df.index) # 行标
通过二维列表创建DataFrame
import pandas as pd
data = [
['小太阳',320.9,100],['鼠标',150.3,50],['小刀',1.5,200]
]
columns = ['名称','单价','数量']
df = pd.DataFrame(data = data, columns = columns)
print(df)
print(type(df))
tips:可以认为在这个例子中,通过传递一个包含三个列表的列表到pd.DataFrame()函数中,创建了三个Series对象,每个Series对象对应一个列。然后将这三个Series对象组合成一个DataFrame对象。DataFrame对象是由多个Series对象按照列方向组合而成的。
通过多个字典创建的特殊形况
# 如果有一个字段的值是固定的则不用故意写成具有相同数据的列表
import pandas as pd
names = ['Alice', 'Bob', 'Charlie']
ages = [25, 30, 35]
fixed_value = 'Example'
data = {'name': names,
'age': ages,
'fixed_col': fixed_value}
df = pd.DataFrame(data)
print(df)
知识点总览
| 属性 | 描述 |
|---|---|
| values | 查看所有元素的值 |
| dtype | 查看所有元素的类型 |
| index | 查看所有行名、重命名行名 |
| columns | 查看所有列名、重命名列名 |
| T | 行列数据转换 |
| head | 查看前N条数据(默认5条) |
| tail | 查看后N条数据(默认5条) |
| shape | 查看行数和列数,返回的是一个元组 |
| info | 查看索引、数据类型和内存信息 |
import pandas as pd
data = [
['小太阳',320.9,100],['鼠标',150.3,50],['小刀',1.5,200]
]
columns = ['名称','单价','数量']
df = pd.DataFrame(data = data, columns = columns)
print(df)
# 查看所有元素的值
print(df.value)
# 查看所有元素的类型
print(df.dtype)
# 查看所有行名重命名行名
print(df.index)
df.index = [f'idx-{i}' for i in range(3)]
print(df.index)
print(df)
# 查看所有列明重命名列名
print(df.columns)
df.columns = [f'col-{i}' for i in range(4,7)]
print(df.columns)
print(df)
# 行列转换
new_df = df.T
print(new_df)
# 查看前N条数据,默认5条
print(df.head(1))
print(df.head)
# 查看后N条数据 默认5条
print(df.tail(1))
print(df.tail)
# 查看行数和列数
print('shape[0]表示行')
print(s0:=df.shape[0],type(s0))
print('shape[1]表示列')
print(s1:=df.shape[1],type(s1))
DataFrame对象的重要方法
知识点预览
| 函数 | 描述 |
|---|---|
| describe() | 查看每列的统计汇总信息,DataFrame类型 |
| count() | 返回每一列的空值的个数 |
| sum() | 返回每一列的和,无法计算空值 |
| max() | 最大值 |
| min | 最小值 |
import pandas as pd
data = {
'名称':['名称','鼠标','小刀'],
'单价':[320.9,150.3,1.5],
'数量':[100,50,200]
}
df = pd.DataFrame(data=data)
print(df)
print(type(df))
# 1.查看每列的汇总统计信息,DataFrame类型
print(df.describe())
# 2.返回每一列的非空值的个数
print(df.count())
# 3.返回每一列的和,无法计算的返回空值
print(df.sum())
# 4.返回每一列的最大值
print(df.max())
# 5.返回每一列的最小值
print(df.min())
在DataFrame对象中的max,min方法在比较字符串的时候比较时的注意点:
- DataFrame 对象的 max 和 min 方法对字符串列进行计算时,是根据字符串的 Unicode 编码值来进行比较的。Unicode 是一种国际标准,用于给所有字符(包括字母、数字、符号等)分配一个唯一的标识符,也就是所谓的编码值。
- 在 Python 中,字符串类型是以 Unicode 编码的方式存储的,每个字符都对应着一个 Unicode 编码值。因此,在对字符串列应用 max 和 min 方法时,实际上是在对其编码值进行比较。
- 具体来说,对于每个字符串,Python 会将其转换为一个由多个 Unicode 编码值组成的序列,并比较这些编码值的大小关系。在这个过程中,编码值小的字符串会被视为更小的值,因此在 min 方法中排在前面;编码值大的字符串则被视为更大的值,在 max 方法中排在前面。
- 需要注意的是,由于不同字符的 Unicode 编码值可能相差很大,因此在使用 max 和 min 方法比较字符串列时,结果可能并不符合人们的预期。例如,对于包含汉字的字符串列,如果不进行特殊处理,可能会出现排序错误的情况。
- 对于包含汉字的字符串,在Pandas中,max()和min()函数同样会按照字典序进行比较。每个汉字都有一个对应的 Unicode 编码,而比较的依据是这些 Unicode 编码。
3. 从DataFrame中查询出Series
- 如果只查询一行、一列,返回的是pd.Series
- 如果查询多行、多列,返回的是pd.DataFrame
- 基于上面的案例
DataFrame对象的loc属性与iloc属性
loc属性
以列名(columns)和行名(index)作为参数当只有一个参数时,默认是行名,即抽取整行数据,包括所有列。
iloc属性
以行和列位置索引(即:0,1,2…)作为参数,0表示第一行,1表示第2行,以此类推。当只有一个参数时,默认是行索引,即抽取整行数据,包括所有列.
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
data = [
[45,56,100],
[56,45,50],
[67,67,67],
]
index = ['张三','李四','王五'] # 设置行标
columns = ['数学','语文','英语'] # 设置列表
df = pd.DataFrame(data = data, index = index, columns = columns)
print(df)
# 提取行数据
print(df.loc['张三']) # 使用索引名称
print(df.iloc[0]) # 使用索引编号
# 提取多行数据
print(df.loc[['张三','李四']])
print(df.iloc[[0,1]])
# 提取连续的多行数据
print(df.loc['张三':'王五']) # 在使用索引名进行切片的时候会包含头和尾
print(df.iloc[0:3]) # 在使用索引编号进行切片的时候包头不包尾
两种方式的特性
- 在使用索引名进行切片的时候会包含头和尾
- 在使用索引编号进行切片的时候包头不包尾
import random
# 切片的特性:[start:stop:step]
data2 = [
[random.randint(i,100) for _ in range(3)] for i in range(10)
]
index2 = [f'NPC{i}' for i in range(1000,1000+10)]
columns2 = ['物理','化学','地理']
df2 = pd.DataFrame(data = data2, columns = columns2, index = index2)
# print(df2)
print(df2.iloc[2:11:2])
print(df2.iloc[::-1])
3.1 查询一列,结果是一个pd.Series
df['year']
type(df['year']) # Series
# 查询多列,结果是一个pd.DataFrame
df[['year', 'pop']]
type(df[['year', 'pop']]) # DataFrame
# 查看一行 loc
df.loc[1]
type(df.loc[1]) # Series
# 查询多行,结果是一个pd.DataFrame
df.loc[1:3]
type(df.loc[1:3]) # DataFrame
抽取指定列的数据
# 数据源
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
data = [
[45,56,100],
[56,45,50],
[67,67,67],
]
index = ['张三','李四','王五']
columns = ['数学','语文','英语']
df = pd.DataFrame(data = data, index = index, columns = columns)
print(df)
# 直接使用列名提取列
print(df[['数学','英语']])
# 提取所有行的数学和英语
print(df.loc[:,['数学','英语']])
print(df.iloc[:,[0,2]])
# 提取连续的列
print(df.loc[:,'语文':])
print(df.iloc[:,1:3])
提取区域数据
# 数据源
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
data = [
[45,56,100],
[56,45,50],
[67,67,67],
]
index = ['张三','李四','王五']
columns = ['数学','语文','英语']
df = pd.DataFrame(data = data, index = index, columns = columns)
print(df)
# 使用loc[],通过column和index获取数据
print(df.loc['张三','数学'],type(df.loc['张三','数学']))
print(df.loc[['张三','王五'],['语文','数学']])
# 抽取指定条件的数据
# 提取语文大于等于60分的数据
print(df.loc[:,'语文'])
print(df['语文']>=60)
print(df.loc[df['语文']>=60])
# 多个条件之间使用&运算法链接,同时每个条件都使用()扩起来
print(df.loc[(df['语文']>=40) & (df['数学']>=50)])
# 查询某条件在指定列表内的内容要使用isin()函数
print(df[df['英语'].isin([100,50])])
数据的增加
数据的增加
- 按列添加数据
- 按行添加数据
- 增加多行多列数据
源数据:
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
data = [
[45,56,100],
[56,45,50],
[67,67,67],
]
index = ['张三','李四','王五']
columns = ['数学','语文','英语']
df = pd.DataFrame(data = data, index = index, columns = columns)
print(df)
-
按列增加
# 采用直接赋值的方式 df['政治'] = [98,99,100] print(df) # 使用loc属性在DataFrame的最后一列增加一列化学 df.loc[:,['化学']] = [100,99,98] print(df) # 使用insert在指定的索引位置插入一列 lst = [110,220,330] df.insert(1,'历史',lst) print(df) -
按行增加
# 新的数据源 df2 = pd.DataFrame(data=data,index=index,columns=columns) print(df2) # 通过loc添加一行数据 df2.loc['陈六'] = [11,22,33] print(df2) # 添加多行-->新建dataFrame对象 new_df = pd.DataFrame(data = { '数学':[67,69], '语文':[12,23], '英语':[45,56] },index = ['小明','小红']) # print(new_df) print(df2) back_df = pd.concat([df2,new_df]) print(back_df)
数据的修改
修改数据
- 修改列标题
columns直接赋值rename修改标题- 修改行标题
index属性- 修改数据
loc和iloc属性
源数据:
import pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
data = [
[45,56,100],
[56,45,50],
[67,67,67],
]
index = ['张三','李四','王五']
columns = ['数学','语文','英语']
# 新的数据源
df3 = pd.DataFrame(data=data,index=index,columns=columns)
print(df3)
修改列标题
# 通过修改columns属性,直接修改无返回值
df3.columns = ['物理','化学','地理']
print(df3)
# 通过rename修改,
# inplace属性为True会直接修改原DataFrame对象,
# 为False则返回新的DataFrame对象
df3.rename(columns = {
'物理':'物理1',
'化学':'化学1',
'地理':'地理1'
},inplace=True)
print(df3)
修改行标题
# 新的数据源
df4 = pd.DataFrame(data=data,index=index,columns=columns)
print(df4)
# 直接赋值
df4.index = list('123')
print(df4)
# 使用rename
df4.rename(index = {
'1':'11',
'2':'22',
'3':'33',
},inplace=True)
# 可以在rename中使用axis来表示修改的效果作用于行还是列
print(df4)
修改数据
# 新的数据源
df5 = pd.DataFrame(data=data,index=index,columns=columns)
print(df5)
# 修改一整行
# 使用loc
df5.loc['张三'] = [111,222,333]
print(df5)
# 使用iloc
df5.iloc[0,:] = [90,90,90]
print(df5)
# 修改列数据
# 使用loc
df5.loc[:,'数学'] = [100,1000,10000]
print(df5)
# 使用iloc
df5.iloc[:,0] = [200,2000,20000]
print(df5)
# 修改某一格的数据
# 使用loc
df5.loc['李四','语文'] = 1000
print(df5)
# 使用iloc
df5.iloc[1,1] = 5000
print(df5)
数据的删除
删除数据
使用
DataFrame对象中的drop方法
df.drop(labels=None,axis=0,index=None,columns=None,inplace=False)特殊参数的使用
名称 说明 labels 表示行标签或列标签 axis 0按行删除,1按列删除 index 删除行,默认None columns 删除列,默认None inplace 是否对元数据进行操作,默认False
# 新的数据源
df6 = pd.DataFrame(data=data,index=index,columns=columns)
# 删除列的三种操作:[], columns, labels
# df6.drop(['数学'],axis=1,inplace=True) # axis=1表示的就是按列删除
# print(df6)
# df6.drop(columns='数学',inplace=True)
# print(df6)
# df6.drop(labels='英语',axis=1,inplace=True)
# print(df6)
df6.drop(['张三'],axis=0,inplace=True) # axis=0表示的就是按行删除
print(df6)
df6.drop(index='李四',inplace=True)
print(df6)
df6.drop(labels='王五', axis=0, inplace=True)
print(df6)
# 带条件的删除
# 删除数学成绩小于60
df7 = pd.DataFrame(data=data,index=index,columns=columns)
# print(df[df['数学']<60])
# 增加条件:仅仅删除第一个元素
df7.drop(df[df['数学']<60].index[1],inplace=True)
print(df7)
e | 是否对元数据进行操作,默认False |
# 新的数据源
df6 = pd.DataFrame(data=data,index=index,columns=columns)
# 删除列的三种操作:[], columns, labels
# df6.drop(['数学'],axis=1,inplace=True) # axis=1表示的就是按列删除
# print(df6)
# df6.drop(columns='数学',inplace=True)
# print(df6)
# df6.drop(labels='英语',axis=1,inplace=True)
# print(df6)
df6.drop(['张三'],axis=0,inplace=True) # axis=0表示的就是按行删除
print(df6)
df6.drop(index='李四',inplace=True)
print(df6)
df6.drop(labels='王五', axis=0, inplace=True)
print(df6)
# 带条件的删除
# 删除数学成绩小于60
df7 = pd.DataFrame(data=data,index=index,columns=columns)
# print(df[df['数学']<60])
# 增加条件:仅仅删除第一个元素
df7.drop(df[df['数学']<60].index[1],inplace=True)
print(df7)